GPU goliaths are devouring supercomputing – and legacy storage can’t feed the beast
Summary
The article explains how the rise of GPU‑centric systems, led by Nvidia’s dense NVL72 racks and similar GPU platforms, has fractured the supercomputing landscape and exposed serious shortcomings in legacy storage designs. AI training and inference workloads create highly random, metadata‑heavy I/O and demand sustained throughput to keep thousands of GPUs fed. Traditional sequential, controller‑bound storage systems struggle with these patterns, forcing a move to software‑defined, NVMe‑first, parallel storage platforms with metadata acceleration, erasure coding and GPU‑aware I/O paths.
Key Points
- Nvidia’s GPU racks (e.g. NVL72) shift the boundary between dense GPU clusters and full supercomputers; large deployments require high‑performance, scalable storage to qualify as true HPC systems.
- AI workloads are changing I/O behaviour from large sequential transfers to spiky, random operations where metadata can represent 10–20% of I/O.
- Per‑GPU throughput needs are substantial (Nvidia guidance: ~0.5 GBps read / 0.25 GBps write per GPU; vision workloads higher), so very large GPU farms need multi‑TBps aggregate bandwidth.
- Parallel file systems and NVMe‑first architectures, plus RDMA/GPU Direct paths, are becoming essential to avoid costly GPU idle time.
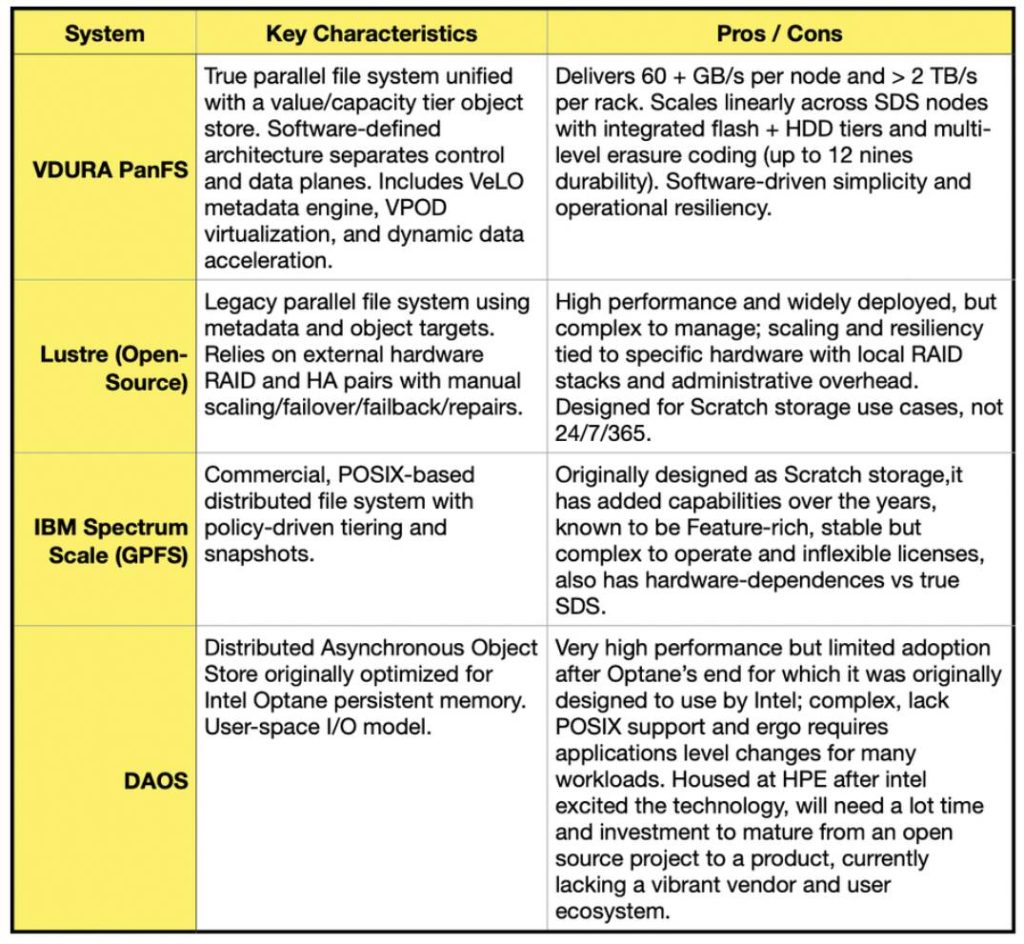
- HPC storage has evolved from proprietary controller systems to software‑defined, mixed‑media platforms that balance NVMe, flash tiers and HDDs for cost and endurance.
- Metadata scaling and low latency are critical; distributed metadata engines (VDURA’s VeLO example) and key‑value metadata approaches are rising in importance.
- Throughput (GBps/TBps) is the dominant metric for AI training, though IOPS and metadata performance remain vital for inference and multitenant workloads.
- Not all file systems are production‑proven; many projects remain research‑grade while commercial SDS platforms now dominate at scale.
Context and Relevance
The piece is timely for anyone involved in HPC, cloud engineering, data centre architecture or AI platform operations. It shows a clear industry shift: GPUs are changing not just compute but the entire storage and networking stack. For organisations planning large‑scale AI or hybrid HPC/AI deployments, storage is now a strategic, cost‑sensitive component rather than just infrastructure plumbing.
Trends highlighted include the move to NVMe and InfiniBand NDR / 400GbE networks, adoption of GPU Direct and RDMA to cut latency, and software‑defined storage that supports mixed media tiering and advanced erasure coding for durability at scale.
Author style
Punchy. This is not lightweight analysis — it flags concrete, operational risks (GPU idle time = cash burned) and explains why storage vendors and HPC teams must rethink architectures now. If you’re responsible for performance, budgets or scaling AI, the details matter: read on or risk costly mistakes.
Why should I read this?
Short version: GPUs are ravenous and old storage systems aren’t built to feed them. If you run or plan to run large GPU clusters, this saves you the pain of learning the hard way — it outlines what to change (NVMe, parallel filesystems, metadata engines, RDMA/GPU Direct) so your GPUs actually get fed and don’t sit idle burning budget.