Shared and language-specific phonological processing in the human temporal lobe
Article Date: 19 November 2025
Article URL: https://www.nature.com/articles/s41586-025-09748-8
Article Image: 
Summary
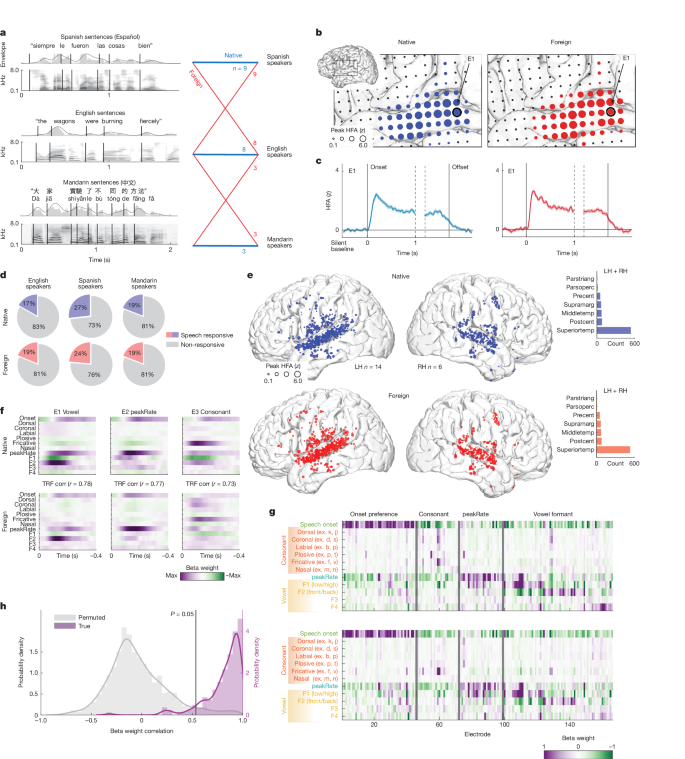
This Nature study used high-density electrocorticography (ECoG) in 34 patients to compare how the human temporal lobe — especially the superior temporal gyrus (STG) — responds to native versus foreign spoken sentences (English, Spanish, Mandarin). The researchers show that basic acoustic–phonetic encoding (vowels, consonant manners, envelope landmarks) is largely shared across languages in the STG. By contrast, experience with a language enhances neural encoding of phoneme sequences and word-level structure (word boundaries, length, frequency, phoneme surprisal). Mid-STG sites in particular carry stronger word-level signals for a listener’s native language; bilinguals encode word-level information for both familiar languages, and English proficiency predicts neural word-boundary decoding performance.
Key Points
- Same STG neural populations respond to both native and unfamiliar languages; acoustic–phonetic tuning is highly conserved across languages.
- TRF analyses show strong cross-language correlations in acoustic–phonetic feature weights (Pearson r ≈ 0.86 across electrodes).
- Language experience selectively boosts encoding of phoneme-sequence and word-level features (word boundary, length, frequency, phoneme surprisal), primarily in mid-STG.
- Neural decoding of word boundaries is significantly better for native speech (AUC native ≈ 0.77 vs foreign ≈ 0.66) and the advantage increases for acoustically ambiguous boundaries.
- Bilingual participants show word- and sequence-level encoding for both languages in overlapping STG populations; proficiency predicts decoding accuracy.
Why should I read this?
Quick take: if you care about how the brain turns sound into words, this is gold. The paper neatly separates what the auditory cortex does regardless of your language (basic sound features) from what tuning and learning add (putting sounds together into words). In short: your ear-brain hears the same building blocks in any language, but experience teaches your STG how to assemble them into language-specific chunks — that’s why foreign speech sounds like a blur even when the raw sounds are recognisable.
Author take
Punchy summary: big-deal, high-resolution human data. This isn’t just fMRI or behavioural inference — direct cortical recordings show that the STG is both a general acoustic processor and a locus for learned, language-specific segmentation. If you study speech perception, developmental phonology, bilingualism or neural encoding models, read the figures and methods closely.
Context and relevance
Where this fits: previous models placed low-level spectrotemporal extraction in auditory areas and higher linguistic processing elsewhere. These results blur that separation by showing language-experience effects (word-level and phoneme-sequence signals) within STG itself. The findings inform theories of language acquisition (why early exposure matters), bilingual representation (shared circuits with proficiency-dependent tuning) and neural models of speech segmentation. They also provide a direct electrophysiological link between acoustic feature encoding and learned phonological composition.