Unpacking the deceptively simple science of tokenomics
Summary
This feature examines the economics of AI inference — the so-called tokenomics — and explains why “more GPUs, more tokens” is an oversimplification. It breaks down how providers optimise tokens per second per dollar per watt (TPS/$/W), why not all tokens are equal, and how software, architecture and precision choices shift the cost/quality trade-off.
Key Points
- Tokenomics centres on maximising tokens per watt and per dollar, but quality metrics (goodput) matter: latency and per-user token rates change the value of tokens.
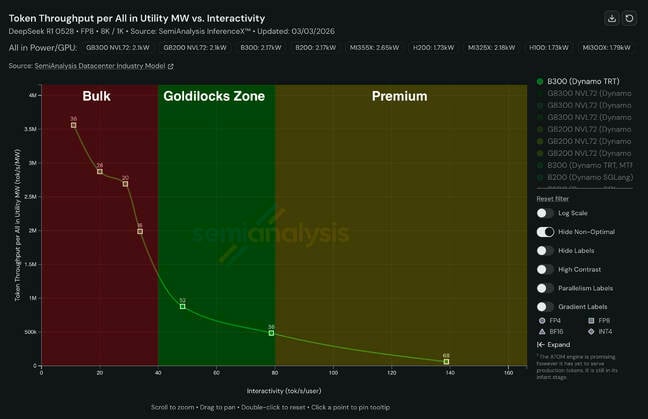
- Inference performance sits on a Pareto curve: bulk cheap tokens (high throughput, low interactivity), premium low-latency tokens, and a “Goldilocks” zone in between.
- Software stacks (vLLM, TensorRT LLM, SGLang, etc.) dramatically affect hardware efficiency; the right engine can shift costs materially.
- Disaggregated compute and rack-scale systems split prefill and decode work across GPUs, improving efficiency for specific workloads and goodput targets.
- Model precision (FP8 → FP4) and quantisation can boost throughput but must preserve accuracy; optimised kernels are required to realise gains.
- Different architectures (rack-scale NVL/Helios vs eight‑way air-cooled boxes) suit different interactivity/throughput points — cost-effectiveness varies accordingly.
- Providers face a “race to the bottom” on commodity tokens; differentiation is now via low-latency hardware, tuning, or specialised services.
Content summary
The article argues that while token output per watt is the headline metric, the economics of inference are governed by goodput: measurable SLAs like time-to-first-token and tokens-per-user. Benchmarks such as SemiAnalysis’s InferenceX reveal a Pareto frontier where throughput and interactivity trade off. Providers tune hardware, software and model precision to hit target points on that curve.
Key levers include inference software (which can make identical hardware behave very differently), disaggregated serving (splitting prompt prefill and decode), rack-scale architectures for higher throughput and lower latency, and lower-precision formats such as FP4 — provided quantisation doesn’t wreck accuracy. The result is a competitive landscape where continuous optimisation and differentiation (low-latency tokens, tuning platforms) matter as much as raw token volume.
Context and relevance
This is important if you run or buy inference services, design datacentres, or follow AI infrastructure economics. It explains why customers see widely varying cost and latency profiles between providers, and why vendors (Nvidia, AMD and others) push both hardware and software updates aggressively. The piece ties together trends in model architecture (MoE), disaggregation, precision advances and the commercial pressures driving optimisation.
Why should I read this?
Quick and blunt: if you care about how AI is actually delivered — not the marketing — this saves you time. It tells you why the cheapest token isn’t always useful, why software choices can be as decisive as silicon, and what to watch for when comparing providers. Read it to avoid buying lots of pretty tokens that don’t meet your latency or quality needs.
Source
Source: https://go.theregister.com/feed/www.theregister.com/2026/03/07/ai_inference_economics/