Investigating the analytical robustness of the social and behavioural sciences
Article Date: 01 April 2026
Article URL: https://www.nature.com/articles/s41586-025-09844-9
Article Image: https://media.springernature.com/m312/springer-static/image/art%3A10.1038%2Fs41586-025-09844-9/MediaObjects/41586_2025_9844_Fig1_HTML.png
Summary
This large multi-team study (stratified random sample of 100 published social and behavioural science studies from 2009–2018) asked at least five independent reanalysts per claim to reanalyse original datasets and compared the outcomes to the published reports. Reanalyses were peer-evaluated for statistical appropriateness and then inspected for robustness across study types and characteristics. The authors quantify how analysts’ reasonable choices lead to variation in reported effect sizes and conclusions and call for routine exploration and communication of this analytic uncertainty.
Key Points
- Sample: 100 studies (claims) published 2009–2018; each claim reanalysed independently by ≥5 analysts.
- Only 34% of reanalyses produced the same result as the original within ±0.05 Cohen’s d; widening the tolerance increased agreement to 57%.
- On the conclusion level: 74% of reanalyses reached the same conclusion as the original study, 24% were inconclusive or found no effect, and 2% reported an opposite effect.
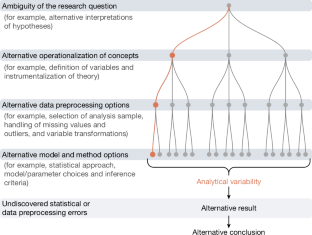
- Analytical choices (variable coding, exclusions, modelling decisions, effect-size conversions) are major sources of variability across reanalyses.
- The project provides open data and code (OSF and GitHub) and recommends standard practices—multiverse/specification-curve approaches, robustness reports and clearer reporting—to capture analytic uncertainty.
Content summary
The team organised a crowd reanalysis initiative: for each selected published claim they recruited multiple independent analysts who followed common instructions but made their own, justifiable analytic choices. Peer evaluators judged the appropriateness of reanalyses. The study then compared effect-size estimates and substantive conclusions across the original analyses and the reanalyses, using predefined tolerance regions (Cohen’s d windows) and categorical outcome comparisons (same effect, inconclusive/no effect, opposite effect).
Findings show substantive heterogeneity. A sizable fraction of reanalysts produced effect sizes and sometimes conclusions that differ enough to matter. The work complements earlier many-analyst projects and specification-curve research, scaling that approach to a representative sample across social and behavioural fields. The authors stress that relying on a single analytic path hides a meaningful and often neglected source of uncertainty.
Context and relevance
Where this fits: the study is part of a growing meta-research movement probing reproducibility, replicability and analytic flexibility across disciplines (psychology, economics, political science, neuroscience). It quantifies the practical impact of the “garden of forking paths” — how defensible analytic choices change results — and provides empirical evidence that single-path analyses are often fragile.
Why it matters to you: funders, editors and researchers making policy or theoretical claims should care that different reasonable analyses sometimes change conclusions. For anyone using social-science findings to inform decisions, the paper argues for routine robustness checks and greater transparency (multiverse analyses, preregistration, robustness reports) so users can judge how contingent results are on analysts’ choices.
Author style
Punchy: this is big‑team meta‑research with hard numbers showing analytic choices matter — not just hair‑splitting, but concrete variability that demands changes to reporting and editorial practice if we want reliable, policy‑useful findings.
Why should I read this?
Short answer: because if you read one rigorous take on whether social‑science results hold up under different, sensible analyses, this is it. It’s a brutally honest, well‑documented look at how often independent analysts agree (and don’t). If you use, publish, review or fund social‑behavioural research, the paper saves you the headache of discovering hidden analytic fragility later — and gives practical pointers for fixing it.
Practical takeaways
- Don’t treat a single analysis as THE answer — report alternative specifications or a multiverse where feasible.
- Use robustness indicators and clearer effect‑size transparency (and link to code/data) to let readers inspect analytic sensitivity.
- Journals and funders should encourage reproducibility practices (registered reports, open materials, synchronous robustness reports).
Data & code
Data and materials: https://osf.io/q5h2c/ — Code repository: https://github.com/marton-balazs-kovacs/multi100